Natural language processing in the detection of fraud in invoices of the municipality of São Paulo (part 1)

1. Introduction
Artificial Intelligence (AI) has been explored to solve problems in several areas of knowledge. In the context of Public Administration, AI can provide automation and efficiency in routine tasks in planning and saving resources (Souza et al. 2022). Tax administrations face many challenges. To fulfill their institutional missions, tax authorities can apply AI to improve tax audits (Nunes; Delgado 2023).
The motivation for the use of AI is noticeable in the daily work of the Tax Administration of the city of São Paulo. In the inspection sector, the analysis of electronic service invoices (NFS-e) allows for the verification of the behaviors of certain taxpayers. In filling out the NFS-e service determination, they use texts that describe services taxed at 5% but apply service codes that have a lower rate, resulting in a lower collection.
We need to attend to the large volume of invoices and taxpayers. Analyzing the Brazilian territory, statistics indicate the issuance of 40.394 billion invoices since 2006 for a total of 226.5 million taxpayers (Receita Federal do Brasil 2024). In the municipality of São Paulo, data from the Municipal Finance Department recorded for the year 2023, 664,215,745 invoices issued for a total of 825,013 taxpayers. The manual analysis of this volume is costly, and the tendency is for taxpayers to use this difficulty to defraud the NFS-e in the way previously explained. Data sets such as the one described are difficult to process, being considered a problem of Big Data (SAS 2024a). This context demands automated analysis, which enables faster decisions and assertive tax schedules, leveraging tax revenues.
This motivates the use of AI techniques and Big Data. Natural Language Processing (NLP) provides a framework of techniques for text analysis (Jurafsky; Martin 2008). Thus, the objective of this work is to apply NLP to find out which are the most frequent terms used in descriptions of higher-rate services but are being used in notes with lower-rate Service Codes.
Works related to the application of NLP in the detection of fraud in invoices have been developed. Marinho (2023) conducted a study with 10,000 invoices from the Federal District. Similarities were calculated between the descriptive text of the product in the note and the official nomenclature of the merchandise by Mercosur. Invoices were considered inconsistent for low similarities, which helped the analysis of auditors. Darrazão et al. (2023) based their study on a set of invoices from Piauí. In the work, starting from a list of 1,000,506 notes, 200 were randomly selected and manually categorized. Classification algorithms were applied, and the results were evaluated. Santos (2022) developed a work to classify descriptive texts of invoices. The database used of 30,000 invoices was provided by the Public Ministry of Paraíba. A sample of the data was manually classified. NLP techniques were applied to classify the grades.
The state-of-the-art solutions depend on manual work and use data sets of reduced representativeness relative to the volume of invoices contemporaneously existing. In addition, no studies were found with the purpose of detecting fraud in the improper use of tax rates and considering the analysis of the most frequent terms in service descriptions.
2. Theoretical Framework
In this section, the concepts related to Hadoop and NLP are explained.
2.1 Hadoop
Hadoop (Apache Hadoop 2006) is a system that extracts, stores, and analyzes large volumes of data (SAS 2024b). According to Figure 1, the Hadoop architecture is formed by a network of computers that distributes the storage and processing of data (Machado 2017).
Figure 1 – Hadoop architecture
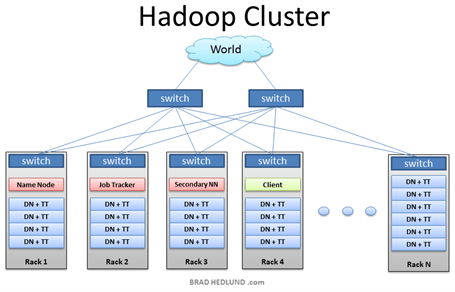
Source: Machado (2017).
It is possible to couple the Spark component to the Hadoop system, as shown in Figure 2, which complements the system with streaming and AI (Techvidvan 2024).
Figure 2 – Integration between Hadoop and Spark
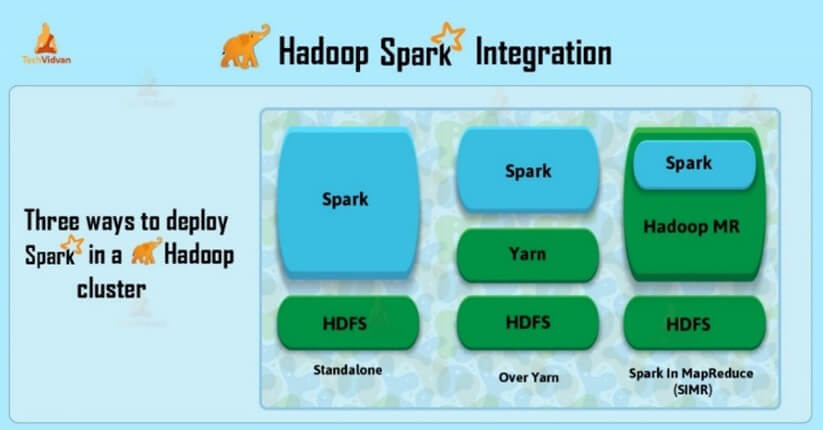
Source: Techvidvan (2024).
2.2 Natural Language Processing
NLP (Jurafsky; Martin 2008) allows computers to perform tasks involving human language and applies to areas such as speech recognition and semantic analysis (Steedman 1996).
2.2.1 Text Preprocessing
The first technique to use in NLP is tokenization, which divides a text into units; these can be words or numbers (Manning; Schütze 1999). Once the text is tokenized, word reduction techniques such as stemming and lemmatization are applied. In the first, prefixes and suffixes are eliminated. In the second, a word is reduced to its lemma: for example, the word ‘friends’ becomes ‘friend.’ Words that are not useful, such as articles and prepositions, are removed and called stop words.
2.2.2 Vector Representation
The model used is bag of words, which creates a vector with a dimension given by the number of different words, storing in each space of the vector the frequency of the respective word (Feldman; Sanger 2006). Some models are based on the co-occurrence of words, using a matrix in which each row is a word and the columns are documents, with the matrix cell being the frequency of the word per document (Jurafsky; Martin 2008).
The term frequency-inverse document frequency (TF-IDF) model is based on the co-occurrence of words. The TF calculates the frequency that a particular term t appears in a document d, and the IDF makes a weighting by the total number of documents and the number of documents in which the term appears. The IDF is given by:

References
- APACHE HADOOP. What Is Apache Hadoop? Website. Available in <https://hadoop.apache.org/>. Accessed on 08/02/2024. Drafted in 2006.
- Darrazão, E.; Amorim, V.; Oliveira, K.; Gomes-Jr, L. Engineering and evaluation of Features for information extraction in invoices. In: Annals of the XVIII regional database School. SBC, 2023. pp. 80-89.
- FELDMAN, R.; SANGER, J. The Text Mining Handbook: Advanced Approaches in Analyzing Unstructured Data. Cambridge University Press, 2006.
- JURAFSKY, D.; MARTIN, J. H. Speech and Language Processing: An Introduction to Natural Language Processing, Computational Linguistics, and Speech Recognition. 2a ed. USA: Prentice Hall PTR, 2008.
- MACHADO, a. Step by Step Guide to create a Hadoop Cluster with 3 Nodes. Article available at <https://blog.4linux.com.br/hadoop-cluster/>. Accessed on: 02/15/2024. Drawn up on 06/06/2017.
- MANNING, C. D.; SCHÜTZE, H. Foundations of Statistical Natural Language Processing. Cambridge, MA: MIT Press, 1999.
- Marine, M. C. Computational strategies based on similarity of texts and exploratory visualization for the identification of inconsistencies in electronic invoices. Monograph. Department of Computer Science, University of Brasilia, 2023.
- NUNES, F. de H. P.; DELGADO, J. de S. The use of Artificial intelligence byTax Administrations. Revista Tributária e de Finanças Públicas, v. 155, N.30, p.73–86, 2023.
- RECEITA FEDERAL DO BRASIL. Portal da Nota Fiscal Eletrônica. 2024. Available in:<https://www.nfe.fazenda.gov.br/portal/sobreNFe.aspx?tipoConteudo=PEhYdxncZBE=&AspxAutoDetectCookieSupport=1>. Accessed: 07 Feb. 2024.
- SAntos, M. T. M. Classification of products on electronic invoices using unstructured textual descriptions. Monograph. Instituto de Computação da Universidade Federal de Alagoas, 2022.
- SAS. Big Data: What is and Why it Matters. 2024a. Available in:<https://www.sas.com/pt_br/insights/big-data/what-is-big-data.html>. Accessed: 15 Feb. 2024.
- SAS. Hadoop: What is and Why it Matters. 2024b. Available in:<https://www.sas.com/en_us/insights/big-data/hadoop.html>. Accessed: 15 Feb. 2024.
- SOUZA, A. M. A.; SADDY, A.; SEYLLER, A. D. M.; BERARDINELLI, A. L.; ARAÚJO, C. M.; SOUZA, D. A. V. G.; PESSANHA, D. P.; COIMBRA, E. M.; LÔBO, F. L. A.; TEIXEIRA, G.; SOUSA, H. A. M.; TORRES, I. M.; CAMPOS, A.; SILVA, J. E.; PEREIRA, J. S. S. S.; GALIL, J. V. T.; ARGENTO, J. R. O.; PINTO, J. O.; FREIRE, K. A.; SILVA, L. F. B.; PEIXOTO, L. B.; SILVA, L. C. Jr.; DAHER, L. E. S. L. T.; SILVA, M. A. M.; TEMER, M.. C.; TEIXEIRA, R. L. C. J.; STRAUCH, T. S. R.; SOUZA, W. V. S. Inteligência Artificial e Direito Administrativo. Centro para Estudos Empírico-Jurídicos (CEEJ), 2022.
- STEEDMAN, M. Natural Language Processing. San Diego: Academic Press, 1996.
- techvidvan. Hadoop Spark Integration: Quick Guide. Article available at < https://techvidvan.com/tutorials/hadoop-spark-integration/>. Accessed on: 02/15/2024.
11,957 total views, 1 views today