Artificial Intelligence, data and biases: notes for tax administrations

Artificial Intelligence (AI) – here treated generically as technologies based on Big Data, data analytics, algorithms, machine learning, neural networks and other techniques for simulating human intelligence – clearly represents a great opportunity of progress for Tax Administrations (TA).
Among the potential uses of digital technologies in TA, we can verify that they provide considerable opportunity for transparency, impartiality, accuracy and efficiency in their procedures. They can also simplify administrative processes, reduce time and costs for taxpayers, strengthen oversight, and keep non-compliant taxpayers under surveillance. In the same way, the processing and analysis of large amounts of data by the TA contributes to the management of public spending and increases the public perception of control by the tax authority., forecasting tax revenues with accuracy and transparency [Almeida, 2020].
All this is based on data. A lot of data. Huge amounts of data – Big Data – characterized by the 5V – variety, volume, volatility, speed, and veracity. The graphic below highlights the elements that make up each feature of Big Data, with its complexity and breadth advancing from the center to the outside.
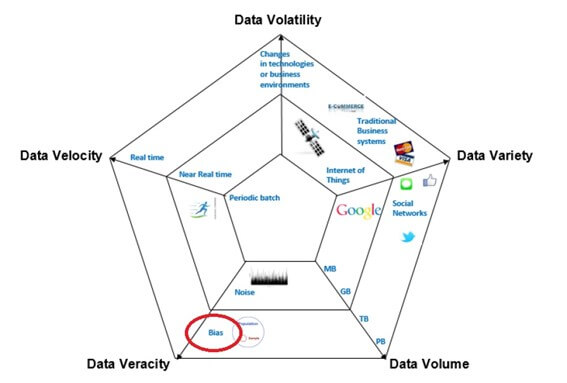
Source: Hammer, 2017
UNECE [I] classifies the relevant data as by-products of the following sources:
- I) Social networks (information of human origin): social networks, blogs and comments, personal documents, photos, videos, Internet searches, text messages, user-generated maps, email.
- II) Traditional business systems (process-mediated data): data produced by public agencies (medical records); data produced by businesses (business transactions, bank records, stock market records, e-commerce, credit cards).
- III) Internet of Things (IoT – machine-generated data): data produced by fixed and mobile sensors, data produced by computerized systems (logs and web logs).
Such quantities, complexities and sources require a strategy and new management models for the TAs’ data, that is, data governance, as explored in [Zambrano, 2022].
Likewise, data protection regulations established by different governments – as the General Data Protection Regulation (GDPR) effective in 2018 for the EU – they imply in new responsibilities for the processing of personal data, based on the following principles: (a) legality, fairness and transparency; (b) collection for specific, explicit and legitimate purposes and not processing in a way incompatible with those purposes – purpose limitation; (c) adequacy, relevance and limitation to what is necessary in relation to the purposes for which they are processed – minimization of data; (d) accuracy and, where necessary, updating – accuracy; (e) storage in a format that allows the identification of the interested parties for no longer than necessary for the purposes of processing the personal data – limitation of storage; and (f) processing in a way that ensures adequate security of personal data, including protection against unauthorized or illegal handling and against accidental loss, destruction or damage – integrity and confidentiality [European Union, 2018].
In AI, the old expression “garbage in, garbage out” is still valid: in any system, the quality of the output is determined by the quality of the input.
The OECD warns that in order for analytics to fulfill its promise of helping tax administrations make better predictions and draw stronger inferences, it needs representative and accurate data sets that capture all the facts about the characteristics and behavior of taxpayers [OECD, 2016]. Special consideration should be given to the training data that is used to build a machine learning algorithm. Thus, data quality assumes fundamental importance for AI.
Initial applications of the use of AI highlight the growing importance of a data quality dimension [II] previously in the ”shadow” of the others: the bias [III] that a set of data can cause. This occurs when variables that adequately capture the phenomenon you want to study and predict are not included. The biases may be in the data or in the algorithm designs. Algorithms, in turn, can also be induced to bias by their training data.
Biased information produces inaccurate results, with serious reflections on users and society. As the European Agency for Fundamental Rights warns, they can generate results that infringe on people’s fundamental rights. For example: a hiring algorithm that prefers men to women; an online chatbot that reproduces racist language after a couple of hours of its launch; automatic translations with gender bias; and facial recognition systems that work better for white men compared to Black women [FRA Focus, 2019].
TAs are extremely sensitive to biases in their data and have also already experienced the widespread negative social and political impacts of AI systems based on biased data and/or algorithms, highlighting the issue of the allocation of benefits for childcare, which happened in the Netherlands [Leahey, 2022]. In another recent case, the US Internal Revenue Service (IRS) admitted that Black people are being disproportionately audited, exposing them to tax penalties. The problem was partially attributed to biases in the case selection algorithm [Adams, 2023 & IRS, 2023].
The possibility of occurrence of bias in the control of tax risks and the selection of taxpayers for the purposes of tax inspections must be considered. When, for example, the model operates and learns only from the data provided on those obligated that were subject to a regularization or sanction. The bias will exist from the moment that the data relating to all fraud cases is not available, but only those that have been detected [López, 2022].
Most real data sets have hidden biases. Being able to detect the impact of bias on the model data and then repair the model is critical.
Considering data from the Internet, currently an important source for TA, it must be considered that the network itself, its scope and type of users already introduce biases in the collected data. As an example, the following indications are relative to the European Union in 2018: internet access is distributed by 98% of high-income households, 74% of low-income households, with a general average of 78%; in the Netherlands, this average is 98%, in Bulgaria, 72%; 11% of people say they never use the Internet, predominantly those between 55 and 74 years old, with a low level of education and women; only an average of 56% of the population uses social networks, including students and high-income people [FRA Focus, 2019]. Therefore, there are limitations for broad and generic use of data from this source, depending on the goals of the application. It should be noted that these considerations are for individuals, not for companies, and that for individuals of tax interest, these biases are smaller.
Although it is said that it is easier to get the bias out of a machine than a human mind, the problem of identification and resolution is still complex, with initiatives of companies, countries and multiple associations working on the issue.
From these efforts, although in the initial stages, interesting orientations are already emerging. In this line, six essential steps to treat biases are presented, as indicated in [Manyika, Silberg, Presten, 2019]:
- 1- Institutional leaders will need to keep up to date in this rapidly evolving field of research;
- 2- When your organization is implementing AI, put in place accountability processes that can mitigate bias. Google and IBM have published frameworks on the topic [IV];
- 3- Participate in fact-based conversations about possible human biases. For example, running an algorithm and comparing its results with decisions made by humans and using “explainable AI techniques” [V] to understand how the algorithm arrived at the indicated result;
- 4- Consider how humans and machines can work together to mitigate biases. Some AI system techniques allow humans to participate in their decisions and indicate the most appropriate directions, or double-check the results beforehand;
- 5- Invest more, get more data and take a multidisciplinary approach in bias research; and
- 6- Invest in more diversity in the field of AI. A more diversified AI community will be better equipped to anticipate, review and detect biases.
Another method of eliminating or reducing biases is proposed in [Uzzi, 2020], using the well-known “blind taste test” (blind taste test), and may provide us with an opportunity to identify and remove decision biases from algorithms, even if we cannot completely remove them from our own mental habits.
The search for the identification, elimination or control of biases in the use of AI continues.
In addition to government and TA research and experiments, hybrid associations cooperate in the development of this field of AI, such as the AI Now Institute (https://ainowinstitute.org), The Alan Turing Institute (https://turing.ac.uk), AI Ethics and Governance of AI Initiative (https://aiethicsinitiative.org) and Partnership on AI (https://partnershiponai.org). Multilateral organizations that support TA, such as CIAT, IDB and IMF, have important roles, especially disseminating experiences and financing initiatives.
Finally, I conclude with what was expressed by Martín López [López, 2022]: “Artificial intelligence cannot be judged as inherently good or bad. In the field of risk control and the fight against tax fraud, it presents an undeniable potential, although there are also risks that must be minimized. But the threat is not the tool itself, but an inappropriate design or use of it. In the abstract, artificial intelligence could help the adoption of more objective decisions, even, than those of a human nature. But, for this, it is required that the selection of the data used, and the configuration and training of the model are adequate and controllable, in order to detect and eliminate the discriminatory biases that may be caused.”
REFERENCES
Adams, C. 2023. “A Black professor has long said what the IRS now admits: The tax system is biased.” May 2008. NBC News Blog. Available at: https://www.nbcnews.com/news/nbcblk/irs-acknowledges-racial-bias-tax-auditing-based-professors-work-rcna85630
Almeida, A. 2020. “The Necessary Dialogue Between Big Data and Trust in Brazil’s Tax Administration.” Oxford University / Blavatnik Scholl of Government, August
European Union. 2018. “General Data Protection Regulation (GDPR)”. Consulted in: https://gdpr-info.eu/
FRA Focus. 2019. “Data Quality and Artificial Intelligence – Mitigating Bias and Error to Protect Fundamental Rights”. European Agency for Fundamental Rights
Hammer, C. et al. 2017. “Big Data: Potential, Challenges and Statistical Implications.” IMF Staff Discussion Note, September
IRS. 2023. Letter from the IRS Commissioner to the United States Senate on the issue of selection for audit. May 15, 2023. Available at: https://www.irs.gov/pub/newsroom/werfel-letter-on-audit-selection.pdf
Leahey, A. 2022. “We Can All Learn a Thing or Two from the Dutch AI Tax Scandal”. Bloomberg Tax Newsletter. July, 12th. Available at: https://tinyurl.com/5ysh56zm
Lopez, J. 2022. “Inteligencia Artificial, Sesgos y No Discriminación en el Ámbito de la Inspección Tributaria.” Crónica Tributaria. Number 182/2022. Available at: https://dx.doi.org/10.47092/CT.22.1.2
Manyika, J., Silberg, J., Presten, B. 2019. “What Do We Do About the Biases in AI.” Harvard Business Review, October 25
OECD. 2016. “Advanced Analytics for a Better Tax Administration”. OECD Publications, Paris
Uzzi, B. 2020. “A Simple Tactic That Could Help Reduce Bias in AI.” Harvard Business Review, November 04
J., R., et al. 2022. “Data Governance for Tax Administrations: A Practical Guide”. CIAT/GIZ. Available at: https://www.ciat.org/data-governance-for-tax-administrations-a-practical-guide/?lang=en
[I] United Nations Economic Commission for Europe
[II] Dimensions: accuracy, completeness, consistency, completeness, reasonableness, timeliness, uniqueness, validity
[III] “A systematic error that can be incurred when sampling or testing selects or favors some answers over others”, Dictionary of the Spanish Language, Royal Spanish Academy
[IV] https://ai .google/responsibility/responsible-ai-practices/
https://www.ibm.com/opensource/open/projects/ai-fairness-360/
[V] Requiring that the conclusions of AI algorithms can be explained is specified in the legal norms of some countries. For more information, see https://www.ciat.org/inteligencia-artificial-explicable-xai-y-su-importancia-en-la-administracion-tributaria/
15,952 total views, 3 views today