Artificial Intelligence: From The Escalation Paradigm To The Return Of Research

Tax administrations have quickly detected the benefits that Artificial Intelligence (AI) techniques can bring to practically all tax processes. Current and planned applications by tax administrations around the world can be glimpsed in publications such as Collosa and Zambrano (2025) and OECD (2025).
Likewise, despite the good results obtained, the high investments made and planned and the climate of optimism surrounding the evolution of the AI area, there are new trends and dark clouds on the horizon that must be considered in the planning by tax administrations.
In this post we will focus on one of the most critical fronts of the current evolution of AI: the increasing pressure on computational capacity and what this anticipates for the future.
Exponential need for computational capacity
The LLMs (Large Language Models) are the basis of sophisticated and long-used AI tools, such as ChatGPT and Gemini. These models are based on two premises: Massive training – they are trained with billions of words (books, articles, code) to learn patterns and relationships between them; Architecture Transformer – they use a neural architecture called Transformer, which processes layered word sequences to understand context.
The Transformers they are the technological “engine” behind ChatGPT (the same T of GPT goes back to this term). To understand them in a simple way, they are a neural network architecture designed to process data sequences, such as human language, in a revolutionary way.
Transformer architecture it is one of the most resource intensive computational technologies that exist. Models based on Transformers they require clusters of thousands of graphics cards (such as the Nvidia H100) running for months for mass training, in addition to daily use in real time to process the questions (inference).
AI processing based on these models requires enormous computational capabilities, promoting exponential growth of data centers.
Major technology companies are planning multi-billion dollar investments in new data centers. Microsoft, for example, planned to invest $80 billion in data centers during the 2025 fiscal year, according to Bloomberg in the InvestNews newsletter. Meta is currently building its largest data center in the world, called the Hyperion Project, in Louisiana, . USA., as part of a multi-million dollar investment focused on AI[1].
By 2023, according to Figure 1, all data centers combined used as much energy as some of the world’s largest economies. By 2030, stimulated mainly by AI, the global demand for electricity for data centers will exceed the total demand of countries such as Russia, Brazil, and Japan.
Figure 1: Electricity demand for data centers (2023) – thousand terawatt-hours
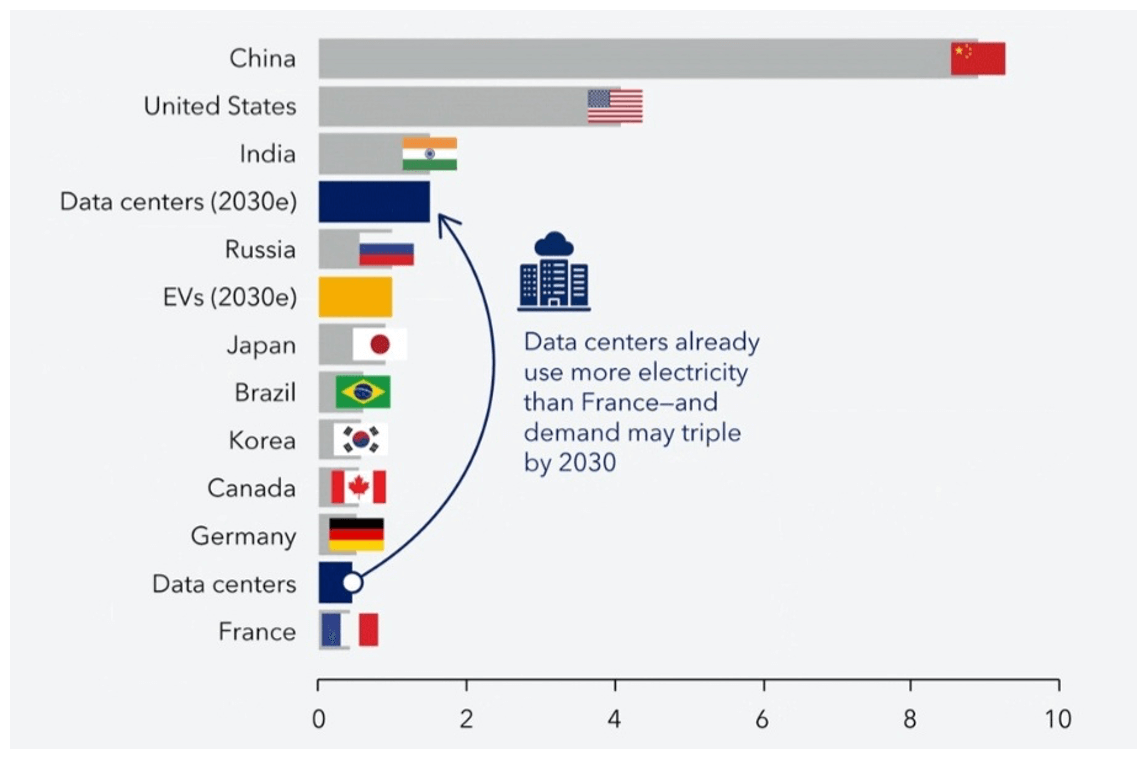
Source: International Energy Agency, Organization of Petroleum Exporting Countries, International Monetary Fund
Simpler AI models require less computational capacity and can provide interesting results, without the breadth and complexity of answers possible in an LLM, but they are feasible only in specific scenarios. The best known are Model Distillation, RAG (Augmented Generation by Retrieval), and Small Language Models (SLM)[1].
The rising costs with AI led Adnan Masood, chief AI architect at UST, to the following comment: “We are entering a strategic inflection point, where innovation, previously considered a competitive necessity, now carries considerable financial risk. The long road to AI mastery is not for the weak. We are facing a future in which companies will have to make strategic decisions about whether to continue pushing the boundaries of AI or risk being left behind… in the “arms race from the AI”[2].
Is there an alternative?
Over the past five years, the evolution of AI has focused primarily on scale. The formula has been clear: the greater the amount of data and processing power applied to the Transformer architecture, greater is also the intelligence and versatility that the model acquires.
Ilya Sutskever, an AI specialist, in interviews with several blogs (Nikhil, 2025), proposed a new thesis: the era of scaling started in 2020 is ending in 2025; we are re-entering the era of research. Adding more and more GPUs will not be enough.
Sutskever and supporters point out issues that will not yet be solved with scaling in current models and need more research. Some of them are mentioned below:
- The current top-of-the-line models suffer from “jaggedness“(irregularity or fragmentation)[3], a concept that describes a contradiction: these models can pass in a complex PhD test, and fail to execute quite simple tasks, entering loops or hallucinating. This disconnect suggests that, while the pre-training (previous training), characteristic of these models, gives a vast knowledge, does not necessarily give them the reliability or perception of a human expert.
- Another challenge is related to the following example: a teenager learns to drive a car in ten or twenty hours, mostly without supervision and without colliding millions of times in a simulation. The challenge is to discover the machine learning principle that allows this kind of rapid and robust generalization, something that scaling fails to capture.
- Also, a topic of interest is the role of emotion in intelligence. In machine learning, a “value function” helps an agent decide whether a situation is good or bad without having to wait until the end. Current AI is based on external rewards (such as a human clicking “thumbs up”) or reinforcement learning environments[4]. Sutskever argues that human emotions, our “intuitions,” are essentially highly efficient and evolutionarily encoded value functions. The idea would be a system that, as humans, learns by doing.
Thus, it is argued that the exponential improvements in AI techniques do not depend on the simple scaling of computational capacity, but mainly on a return to laboratories and deep research projects aimed at the development of new learning paradigms.
Impacts on tax administrations
The adoption of AI in tax administrations is a complex issue and does not only consider the risks in the evolution of infrastructure costs, discussed in this post, and the exposure to an “AI bubble.”
The decision-making regarding critical aspects for the success of the initiative covers other components, such as architectures and suppliers (avoid vendor lock-in and accelerated obsolescence); models to be used and the strategy to adopt them; privacy and ethics issues; establishing ROI (KPIs) based on business (e.g., reducing the tax gap) and not on “modernity”.
Above all this are the data, fundamental for any defined strategy. Therefore, establishing data governance should be a top priority.
It is also important to follow the progress of the area for informed decision-making.
Bibliography:
[1] See https://bit.ly/3Lkunlr
Collosa, A. and Zambrano, R. (2025). The AI is already here. CIAT Blog. Available at: https://www.ciat.org/la-ia-ya-esta-aqui/
Nikhil. (2025). Ilya Sutskever: “Age of Scaling is Over. The Age of Research Has Begun.” Blog on Medium, November 6, 2025. https://medium.com/modelmind/ilya-sutskever-age-of-scaling-is-over-the-age-of-research-has-begun-7506c4d0a89a
OECD (2008). Tax Administration 2025: Comparative Information on OECD and other Advanced and Emerging Economies. OECD Publishing, Paris. https://doi.org/10.1787/cc015ce8-en
Wu, K., Jian, X., Du, R., Chen, J., & Zhou, X. (2023). Roughness Index for Loss Landscapes of Neural Network Models of Partial Differential Equations. https://arxiv.org/pdf/2103.11069
References:
[1] For more information, access (1) about distillation – IBM: https://bit.ly/49qQ2lc ; (2) about RAG – Google: https://cloud.google.com/use-cases/retrieval-augmented-generation?hl=es
[2] See https://www.ibm.com/think/insights/ai-economics-compute-cost
[3] Academic description of the concept can be found in Wu et al. (2023)
[4] Reinforcement Learning (Reinforcement Learning or RL) is an AI training method based on the principle of trial and error, remarkably similar to how a pet is trained or how a human learns to play a video game. Unlike traditional learning (where you give the AI “question and answer” examples), in RL the AI learns by interacting with an environment and receiving rewards or punishments (source: keytrends.ai ).
2,728 total views, 6 views today