Un ejemplo muy muy simple sobre el uso de Inteligencia Artificial en la Administración Tributaria

Con mucha frecuencia escuchamos, leemos o vemos reportajes, anuncios o noticias sobre la aplicación de inteligencia artificial, y particularmente del aprendizaje de máquinas – machine learning – para resolver problemas o volver su solución más eficiente.
La administración tributaria, por supuesto, puede beneficiarse también de la aplicación de estas tecnologías para mejorar la gestión de riesgo, procesar grandes cantidades de información en tiempo cercano al real, o para brindar servicios y asistencia técnica con mejores niveles de servicio. Y aunque esta afirmación es muy razonable, en nuestra opinión, puede quedar todavía en una zona algo abstracta. Algunas personas, tal vez, querrán hacer una pregunta al escuchar esa afirmación anterior: «Ya, pero ¿cómo?».
Precisamente aquí voy a tratar de responder con un ejemplo sencillo, muy sencillo, sobre la potencia que tiene la inteligencia artificial dentro de la administración tributaria en diferentes procesos.
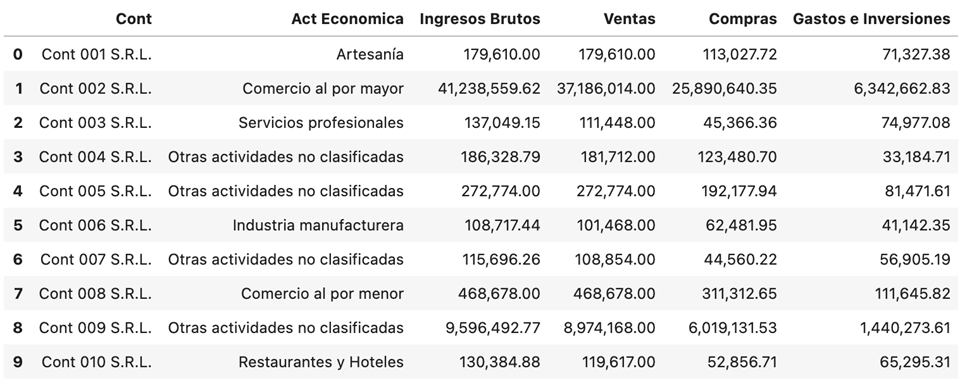
Vamos a suponer que nos encontramos en una agencia de una administración tributaria geográficamente localizada. Esto nos permite asumir que no hay demasiadas diferencias entre los contribuyentes al estar, por ejemplo, unos en una zona desarrollada de una gran ciudad y otros en una zona residencial o en una pequeña población del interior. En esta agencia se trabaja con mil contribuyentes. Nuestro conjunto de trabajo sobre esos contribuyentes incluye unos pocos datos del registro y unos campos de su declaración de impuesto del último ejercicio. A continuación vemos los primeros 10 registros de estos contribuyentes.
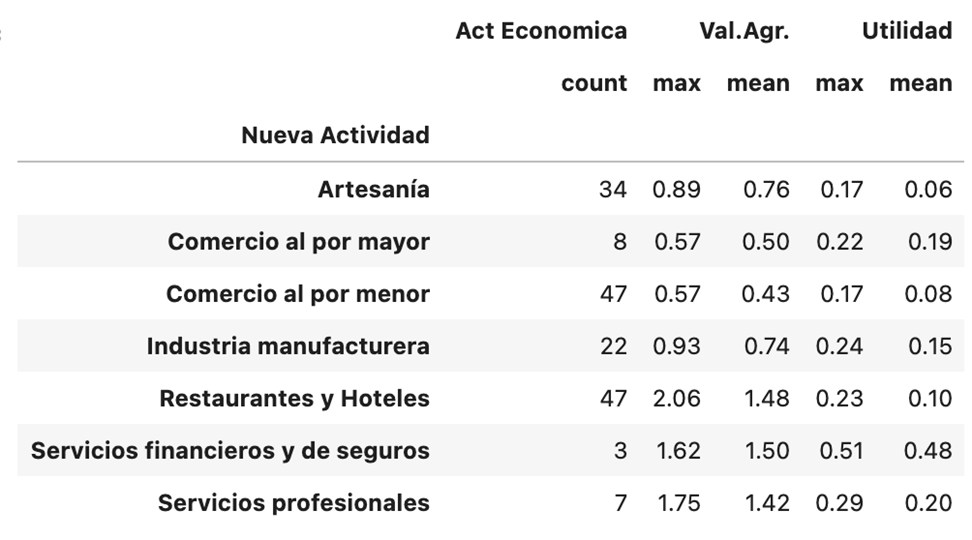
La siguiente tabla nos permite evaluar por cada actividad económica los valores máximos y el promedio:
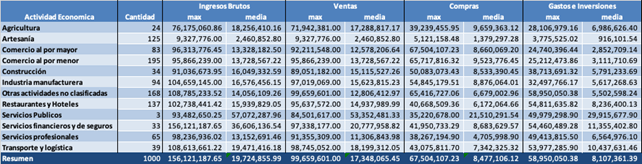
Una rápida revisión de los valores máximos y mínimos y de la distribución de frecuencia de actividad económica nos permite observar que el número de contribuyentes en la actividad económica servicios públicos es muy pequeño (3), mientras destacan por su número los contribuyentes en actividades económicas de comercio al por menor, restaurantes y hoteles y los que se encuentran en otras actividades no clasificadas. En cuanto a los valores de medias y máximos se observa que son en valores significativamente más pequeños para el sector de artesanías mientras son mayores en servicios financieros y de seguros.
Para profundizar con nuestro análisis de los datos estudiaríamos la distribución de los valores para cada variable por actividad económica, observando que para cada variable el comportamiento es relativamente similar en cada actividad económica, con valores muy cercanos para todos los cuartiles en artesanía y servicios públicos, y muchos valores fuera de rango – outlieres – en las demás actividades económicas, pero donde no se observa grandes diferencias de comportamiento.
Dando un paso más podemos agregar dos campos calculados en nuestro ejemplo. El primero, también simplificando, los llamaremos Utilidad:
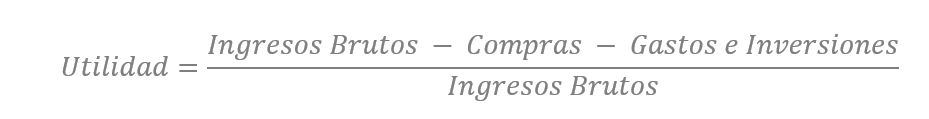
El segundo, lo llamaremos Valor Agregado,
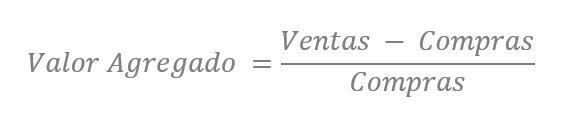
Los valores de las dos características nos permiten identificar que la actividad económica de servicios financieros y de seguro cuenta con los contribuyentes que en promedio tienen mayor utilidad, mientras que en la columna de valor agregado hay mayor amplitud con porcentajes que van en media para la actividad de algo más de 40% a casi 150%.
Cada actividad económica tiene una distribución distinta en las dos variables, siendo Otras actividades no clasificadas, la única categoría que tiene valores fuera de rango en Utilidad, mientras que la amplitud entre los cuartiles en el caso de valor agregado es extremadamente notable. Esto nos induce a pensar que los contribuyentes en esta categoría tienen un comportamiento muy disímil entre ellos.
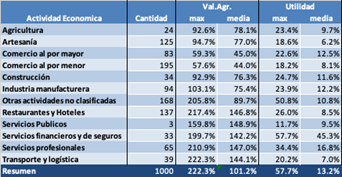
Si graficamos cada uno de los puntos correspondientes a cada uno de los mil contribuyentes con las coordenadas de Valor Agregado en el eje X y Utilidad en el eje Y tendríamos el siguiente gráfico
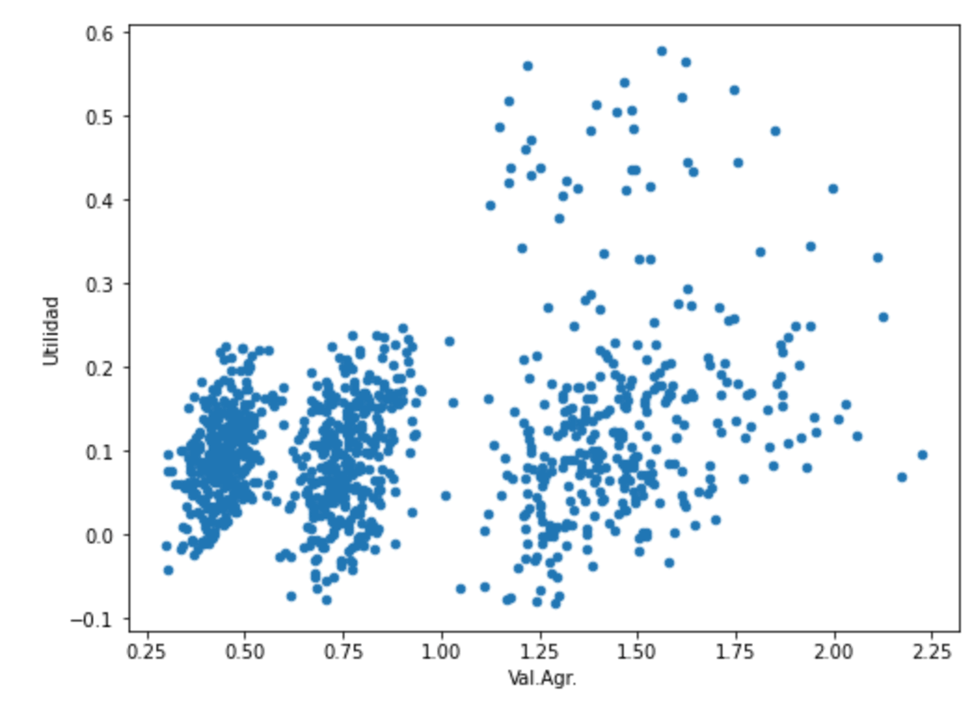
Y las herramientas de inteligencia artificial nos permiten identificar en realidad 4 grupos de contribuyentes, por su comportamiento:
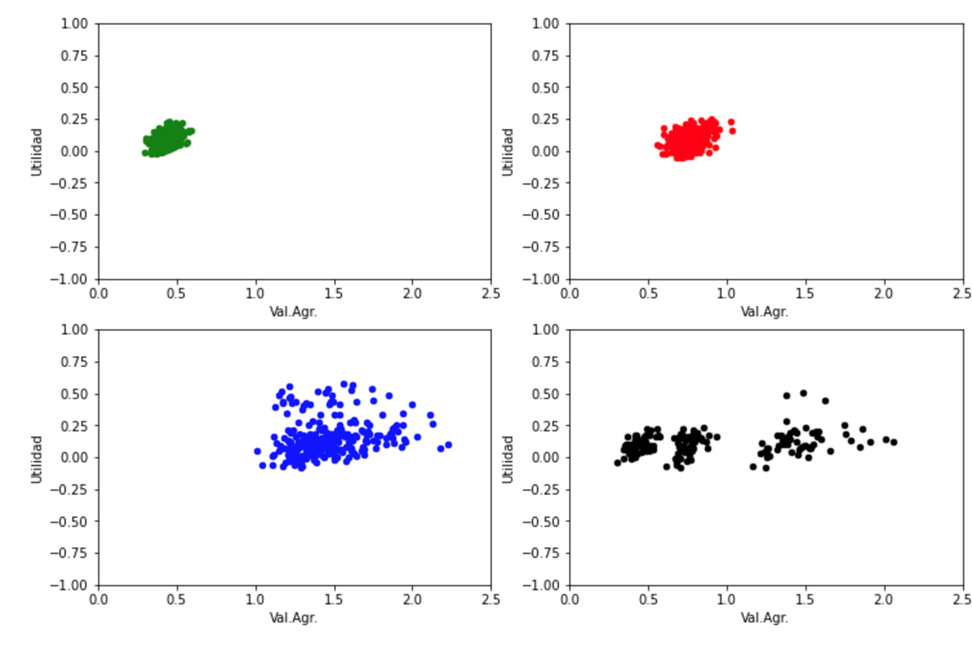
El primero, corresponde las actividades económicas Comercio al por mayor y comercio al por menor, pintadas en verde. El segundo a las actividades económicas de Agricultura, Artesanía, Construcción e Industria Manufacturera; pintados en rojo. El tercero, corresponde a Restaurantes y Hoteles, Servicios Públicos, Servicios Financieros y de Seguros, Servicios Profesionales y Transporte y Logística, pintados en Azul. El cuarto grupo, pintado en negro, corresponde a Otras Actividades No Clasificadas, que tiene puntos en cada uno de los grupos anteriores.
Podemos de manera arbitraria identificar estos grupos como «Comercio», grupo 1. Transformación de materia primera, grupo 2; Servicios grupo 3, y No correctamente clasificado grupo 0.
Encontramos contribuyentes con pérdidas y ganancias en todos los grupos, si bien la amplitud de los rangos para Comercio es mucho más pequeña que para Servicios. Para Valor Agregado, notamos claramente diferencias significativas entre los tres grupos, mientras que los contribuyentes no clasificados presentan una amplitud de valores que cubre todo el espectro de los demás contribuyentes. Nuestra hipótesis es que esos contribuyentes en realidad tienen una actividad económica correspondiente con alguna de las actividades identificadas en los otros grupos.
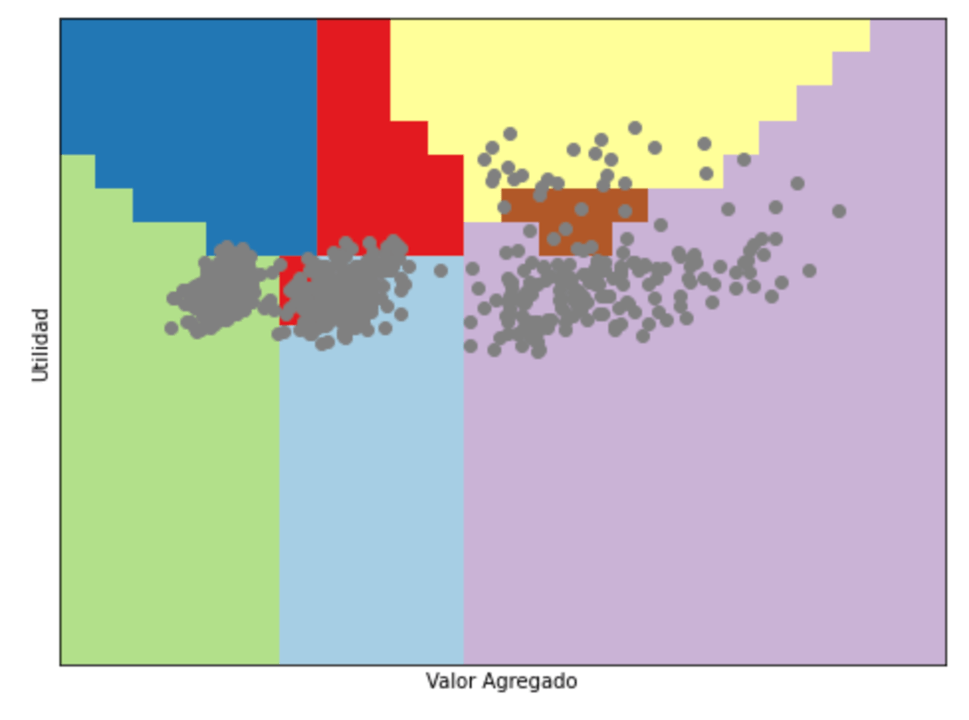
Aquí es donde utilizaremos herramientas de aprendizaje de máquina. En este caso vamos a utilizar uno de los algoritmos de clasificación más sencillos denominado «k vecinos más próximos«, en donde a partir de una población conocida, se determina los k vecinos más próximos y se determina que ese punto debe corresponder a la categoría que predomina entre esos puntos mayoritarios. Es decir, que si para un punto cualesquiera, la mayoría de los puntos más cercanos son del tipo Comercio, el algoritmo determinará que esa es la categoría que le corresponde, aun si existen puntos de otras categorías. Esto puede ilustrarse con el siguiente gráfico que determinaría para nuestra población de contribuyentes esta división:
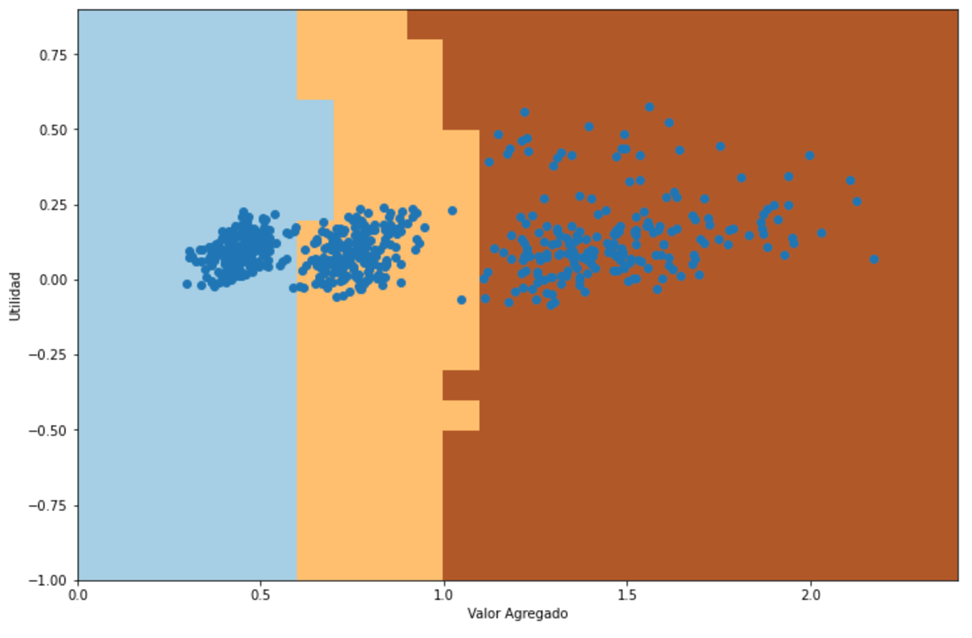
Con este algoritmo, cualquier punto que caiga en la zona celeste será clasificado como Comercio, en la zona crema como de Transformación y en la zona marrón oscura será clasificada como Servicios.
Para entrenar el algoritmo y probar su efectividad se separan de manera aleatoria el conjunto de 832 contribuyentes con actividades bien clasificadas en un grupo de entrenamiento, en nuestro caso 75% aproximadamente, y el conjunto de prueba (25%) para comprobar la efectividad del algoritmo. Los valores de efectividad de este algoritmo con estas divisiones son de 100% para el conjunto de entrenamiento y de 99% para el conjunto de prueba. Esto significa que, si aplicamos para los 168 contribuyentes que están en la categoría de Otras Actividades no Clasificadas, podríamos conocer con bastante precisión si en realidad se dedican a actividades de Comercio, de Transformación o de Servicios.
Esta división artificial que he realizado aquí, aunque útil, no deja de ser arbitraria. Tenemos la opción de aplicar el mismo algoritmo, no para identificar cuál de estos tres conjuntos agregados de actividades le correspondería a cada contribuyente con la actividad económica sin clasificar, sino para buscar la actividad económica propiamente dicha. El siguiente diagrama nos ilustra como se correspondería el algoritmo
En este caso, con la clasificación a las 10 actividades económicas identificadas, la efectividad de nuestro algoritmo sería de 67% para el conjunto de entrenamiento y de 65% para el conjunto de prueba. Estos porcentajes de efectividad no son tan espectaculares como los de la clasificación anterior, pero aun así nos dejan una probabilidad mucho mayor a la de acertar con la clasificación de manera aleatoria. Se observan áreas más complejas con posibles superposiciones como en los sectores de Comercio a la izquierda, con comercio al por mayor en azul y al por menor en verde.
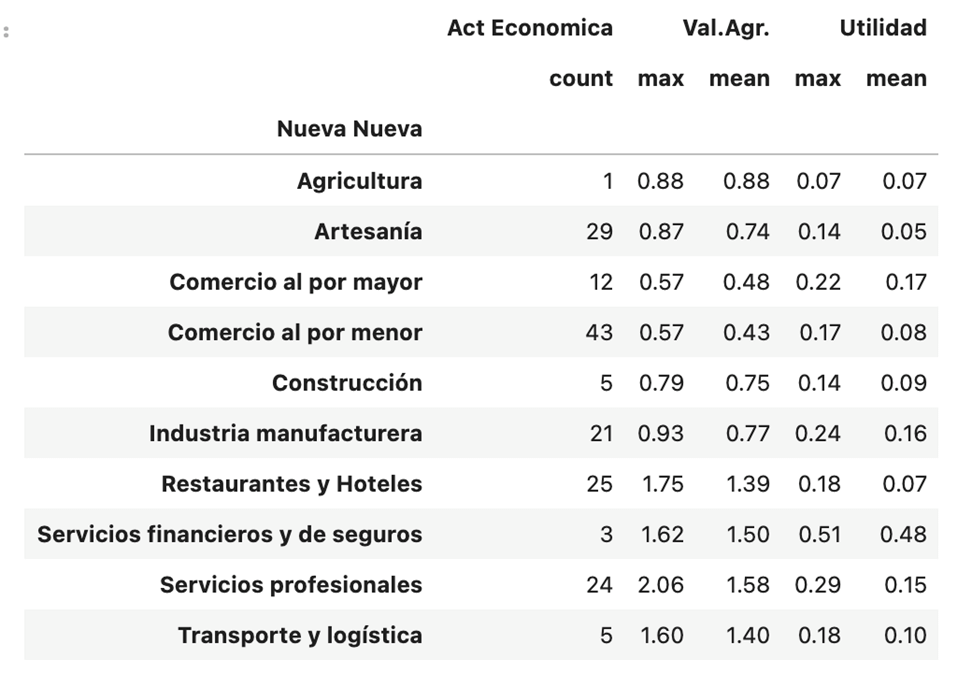
Aplicando este algoritmo de clasificación a los 168 contribuyentes sin clasificación correcta de actividad económica tendríamos la siguiente distribución.
Este resultado considera únicamente las variables Utilidad y Valor Agregado. Una mejor aproximación vendría de realizar el análisis utilizando todas las 6 variables disponibles y un algoritmo más complejo, pero que se acerque mejor a nuestro conjunto de datos. Aunque ya no es tan sencillo de visualizar ya que serían gráficos en n dimensiones y utilizando algoritmos de regresión tipo Logit para clasificación, (que en términos prácticos trata de determinar la probabilidad de que, en nuestro caso, tenga una determinada actividad o no, la siguiente actividad o no, y así sucesivamente) tendríamos: un porcentaje de efectividad para el conjunto de entrenamiento de 83% y para el conjunto de test de 75%, mucho mejores que los observados en el ejemplo anterior.
Aplicando este algoritmo a los 168 contribuyentes sin clasificación adecuada tendríamos la siguiente distribución.
Conclusión
El uso de herramientas de aprendizaje de máquinas nos permite aquí, a partir de datos que tenemos identificar con una posible actividad económica real para los contribuyentes que en esta agencia tenían una categoría de No Clasificados.
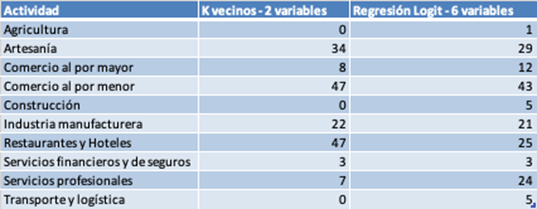
El ejemplo es ilustrativo por varias razones. Una primera conclusión es que no existe un solo algoritmo de aprendizaje de máquina que puede aplicarse a nuestro problema. Al contrario, pueden ser muchos, algunos adecuados a partir de métodos existentes y algunos por crear. En nuestro ejemplo, como se ilustra en la tabla a continuación, el segundo algoritmo utilizado, más complejo matemáticamente y con más variables de datos para contribuir hace un mejor trabajo.
En la administración tributaria sabemos que una correcta identificación de la actividad económica del contribuyente es importante. Puede ser determinante en la gestión de riesgo, puede tener implicaciones en el cumplimiento tributario, puede abrir espacios a beneficios específicos asociado a una actividad. Este ejercicio sencillo, en nuestra hipotética agencia nos ha permitido en un tiempo extremadamente corto asignar una probable actividad económica a 168 contribuyentes sin clasificación. Solo a partir de los datos disponibles, sin contactar a los contribuyentes. Un mecanismo tradicional habría requerido seguramente algo más de un par de meses-persona para verificar caso a caso la actividad económica de cada uno de esos contribuyentes.
Por supuesto que en nuestro ejemplo, este incremento de eficiencia se nota, pero tal vez no asombre. Ahora, si pensamos no en una agencia con 1000 contribuyentes, sino en un conjunto con varios cientos de miles o millones de contribuyentes, este incremento de eficiencia puede ser significativo.
Nuestro ejemplo es simple, parte de un pequeño conjunto de datos sintéticos. En la realidad nuestro conjunto de datos disponible crecería significativamente. Deberíamos sumar las declaraciones de períodos anteriores, la información recibida de terceros (como bancos u operadores de tarjetas de crédito) o información tan detallada y voluminosa como la que viene de factura electrónica que, para citar un caso, podría ayudar a discriminar a partir de los montos más frecuentes de las operaciones individuales a distinguir muy apropiadamente el comercio al por mayor o al por menor. Estos datos estructurados podrían complementarse con otros menos evidentes, como por ejemplo la razón social de los contribuyentes, (“Ferretería el repara todo”, nos da una buena idea de lo que puede hacer ese contribuyente), sumadas a fuentes no estructuradas, como la publicidad que los contribuyentes despliegan en medios de comunicación y redes sociales.
No tendremos entonces un conjunto de 6 variables, como en nuestro ejemplo, sino de miles (tal vez más) elementos de información asociados a cada contribuyente. Las oportunidades de hacer cosas interesantes son enormes, tanto como serán complejos los desarrollos necesarios para lograrlas. Es un terreno fértil en el que esperamos podamos contribuir con nuestros países miembros compartiendo experiencias, lecciones aprendidas o, por qué no, desarrollando algoritmos apropiados para nuestro entorno, disponibles para las administraciones que quieran utilizarlos. Ese es precisamente el objetivo atrás de la idea que tenemos de crear un Centro de Analítica Avanzada e Inteligencia Artificial dentro del CIAT, con la participación de “científicos de datos” y gente interesada de nuestras administraciones, de gente de la academia, empresa privada y consultores independientes, operando fundamentalmente con herramientas de código abierto y produciendo conocimiento, buenas prácticas y algoritmos en aspectos tan variados como verificación de la calidad de datos, anonimización y, por supuesto, uso de inteligencia artificial, que aunque lo parezca no es magia.
Saludos, suerte y feliz año, que venga con vacunas.
15,741 total views, 13 views today
19 comentarios
Gracias Raúl, Gracias Santiago!!
Gran aporte para mostrar las distintas aplicaciones que tienen estas herramientas, que no solo no están lejos, sino tambien que están muy cerca de nuestras tareas habituales.
Gracias Raulito y Santiago , excelente artículo que muestra como de una manera «practica y fácil» se puede abordar y desenredar un problema común de todas las AATT , hoy por hoy , de solución nada fácil .
Abrazo,
Muy buen artículo saludos
Muchas Gracias!
Cuan útil puede ser la Inteligencia Artificial!
Qué el 2021 sea positivo para la Humanidad!
Muito bom! Parabéns!!
Estimados Raúl y Santiago, felicitaciones por el artículo. Creo que el CIAT va por buen camino.
Raúl y Santiago, felicitaciones, execelente artículo de divulgación de los temas.
Me interesó especialmente conocer que el CIAT pretende crear un Centro de Analítica Avanzada e Inteligencia Artificial.
Espero que sea publicado otro POST cuando tengan estructurado el funcionamiento de este Centro, financiamiento, modelo operativo, etc.
Abrazo
Felicitaciones! Muy buen artículo y de suma utilidad para entender el funcionamiento práctico de la IA. Sobre todo entender que se puede utilizar de múltiples maneras, adaptable a la necesidad de cada AATT.
Muy buen articulo; me queda la duda en cuanto al desarrollo de la IA, el lugar que tendra la subjetividad, interpretacion y aplicacion de la norna juridica tributaria.
Saludos
Muito bom, pelo artigo realmente será útil…
Felicitaciones por el articulo, viene como una pequeña muestra, como bien lo manifiestan, de lo que se puede lograr con el uso de la AI, pero sin embargo creo que seguimos en el mismo esquema de tratamiento de la información Ex-Post, o sea con valores históricos cuando sabemos que el gran problema de las AA.TT. es la brecha entre las acciones de control (análisis de datos históricos) y el avance tecnológico de la actividad privada para sacar ventaja de esta, soy de opinión modestamente, que deberíamos ver una acción alternativa en el Blockchain como una técnica de rastreo y a partir de ella la aplicación de métodos de gestión de riesgo sin posibilidad de fallas en la determinación y acciones de control de tributación.
Saludos.
Excelente articulo. Una pregunta. que herramientas utilizaron. Yo, uso R y RStudio creo que se puede implementar muy fácil con esta herramienta la AI. Me gustaria publicaran que software utilizaron y los códigos para poder tener una mejor perspectiva de los resultados.
Muy interesante y complejo.. crear el centro de analítica avanzada del CIAT me parece fundamental para la labor que hacen… mucha suerte y decisión… saludos
Muy buen articulo, excelente ejemplo de aplicación de algoritmo de clasificación de IA.
excelente explicación!
Excelente y didáctico aporte para la difusión de una herramienta de validez indiscutible en las administraciones a fin de conocer entre otras, actividades no identificadas, con ubicación de sus responsables y control de sus conductas, a través del aporte de una tecnología que amerita ganar posición en el CIAT para facilitar a sus miembros su utilización en la mejora del cumplimiento.
Estas herramientas, creen algunos pensadores sociales, tambien anuncian el riesgo de un futuro con el control absolutista de la conducta del hombre.
Felicitaciones a ambos por el uso inteligente de la inteligencia artificial. Muy bueno el artículo. Cordiales saludos
Buenos días estimados Raúl Zambrano y Santiago Diaz de Sarralde, con gran satisfacción veo después de algunas semanas publicado un artículo vuestro, cuya autoria se caracteriza por ser didáctica y muy amplia en cada tema, no obstante, y por lo general en fuentes diferentes al CIAT vemos que optan por el uso de tecnicismo, resultando poco accesibles y son escasos en detalles.
Todo lo contrario sucede con el articulo con el cual Ustedes, generosamente premian la lectura y comprensión de quienes tenemos sano interés por la Ingeniería aplicada a la Tributación. Entonces, Felicitaciones y Gracias!!!!
Como bien nos muestran, el uso de estos mecanismos o herramientas, resulta ventajoso tanto para las Administraciones como para los Contribuyentes.
Para ambos, en cuanto al costo operativo, de la intevencion y de la atención de la misma, lo cual deja en libertad de redireccionar recursos logísticos, económicos y de recursos humanos a otras areas, sin que por el efecto, resulte mermada la productividad y/o eficiencia de los procesos de las partes.
Lo cual, se explica básicamente, en que, el uso de las herramientas de ingeniería nos permite, desde siempre, predictibilidad, de los resultados y por ende, la disminución del margen de discrecionalidad, no solo del operador, sino también para la entidad que las aplica; en la medida del diseño del Algoritmo.
De tal manera que, en el uso de ciertas herramientas de ingeniería en la aplicación de los procedimientos tributarios, radican algunas de las capacidades para anticiparse y garantizar por parte de los contribuyentes, así como, por parte de las Administraciones, la reducción de subjetividades, excesos u errores en los procesos y control, y en especial del resultado de los mismos, proporcionando mayor seguridad al Administrado.
Y por supuesto que, resulta muy interesante la iniciativa de creación de un Centro de Analítica Avanzada y de Inteligencia Artificial dentro del CIAT.
Gracias Raul. Mui Bueno