Inteligencia Artificial: Del Paradigma Del Escalamiento Al Retorno De La Investigación

Las administraciones tributarias han rápidamente detectado los beneficios que las técnicas de Inteligencia Artificial (IA) pueden aportar a prácticamente todos los procesos tributarios. En publicaciones como Collosa y Zambrano (2025) y OECD (2025) se pueden vislumbrar aplicaciones corrientes y planeadas por administraciones tributarias alrededor del mundo.
Asimismo, a pesar de los buenos resultados obtenidos, las altas inversiones realizadas y planeadas y el clima de optimismo que cerca la evolución del área de IA, hay nuevas tendencias y nubes oscuras en el horizonte que deben ser consideradas en la planificación por las administraciones tributarias.
En este post nos centraremos en uno de los frentes más críticos de la evolución actual de la IA: la presión creciente sobre la capacidad computacional y lo que ello anticipa para el futuro.
Necesidad exponencial de capacidad computacional
Los LLM (Grandes Modelos de Lenguaje) son la base de herramientas de IA sofisticadas y de larga utilización, como ChatGPT y Gemini. Estos modelos están fundados en dos premisas: Entrenamiento masivo – se entrenan con miles de millones de palabras (libros, artículos, código) para aprender patrones y relaciones entre ellas; Arquitectura Transformer – utilizan una arquitectura neuronal llamada Transformer, que procesa secuencias de palabras en capas para comprender el contexto.
Los Transformers son el «motor» tecnológico detrás de ChatGPT (la misma T de GPT remonta a este término). Para entenderlos de forma sencilla, son una arquitectura de red neuronal diseñada para procesar secuencias de datos, como el lenguaje humano, de una manera revolucionaria.
La arquitectura Transformer es una de las tecnologías más intensivas en recursos computacionales que existen. Modelos basados en Transformers requieren clústeres de miles de tarjetas gráficas (como las Nvidia H100) funcionando durante meses para el entrenamiento masivo, además del uso diario en tiempo real para procesar las preguntas (inferencia).
El procesamiento de IA basado en estos modelos requiere enormes capacidades computacionales, promocionando crecimiento exponencial de los centros de datos.
Grandes empresas de tecnología planean inversiones por miles de millones de dólares en nuevos centros de datos. Microsoft, por ejemplo, planeaba invertir 80 mil millones de dólares en centros de datos durante el año fiscal 2025, conforme Bloomberg afirma en la newsletter InvestNews. Meta está construyendo actualmente su centro de datos más grande del mundo, denominado Proyecto Hyperion, en Luisiana, EE. UU., como parte de una inversión multimillonaria centrada en la IA[1].
En 2023, conforme la Figura 1, todos los centros de datos combinados utilizan tanta energía como algunas de las economías más grandes del mundo. Para 2030, estimulado principalmente por la IA, la demanda global de electricidad para los centros de datos superará la demanda total de países como Rusia, Brasil y Japón.
Figura 1: Demanda de electricidad para centros de datos (2023) – miles de teravatios/hora
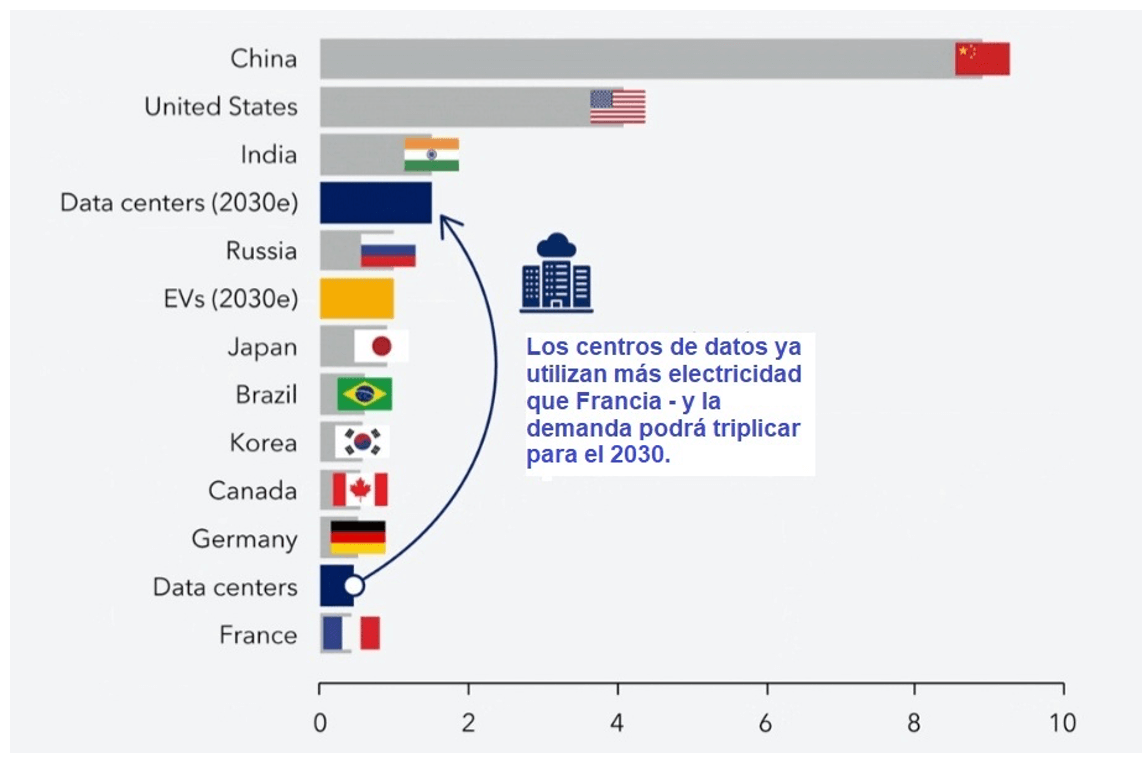
Fuente: Agencia Internacional de Energía, Organización de los Países Exportadores de Petróleo, Fondo Monetario Internacional
Modelos más sencillos de IA requieren menor capacidad computacional y pueden proveer resultados interesantes, sin la amplitud y complejidad de respuestas posibles en un LLM, pero son factibles solamente en escenarios específicos. Los más conocidos son la Destilación de Modelos, RAG (Generación Aumentada por Recuperación) y Modelos de Lenguaje Pequeños (SLM)[1].
Los costos crecientes con IA conllevaron Adnan Masood, arquitecto jefe de IA en la empresa UST, al siguiente comentario: “Estamos entrando en un punto de inflexión estratégico, donde la innovación, antes considerada una necesidad competitiva, ahora conlleva un riesgo financiero considerable. El largo camino hacia el dominio de la IA no es para los débiles. Nos enfrentamos a un futuro en el que las empresas deberán tomar decisiones estratégicas sobre si seguir ampliando los límites de la IA o arriesgarse a quedarse atrás… en la carrera armamentística de la IA”[2].
¿Hay alternativa?
En los últimos cinco años, la evolución de la IA se ha centrado primordialmente en la escala. La fórmula ha sido clara: cuanto mayor la cantidad de datos y capacidad de procesamiento aplicados a la arquitectura Transformer, mayor también es la inteligencia y versatilidad que el modelo adquiere.
Ilya Sutskever, especialista en IA, en entrevistas con varios blogs (Nikhil, 2025), propuso una nueva tesis: la era del escalamiento iniciada en 2020 está finalizando en 2025; estamos reentrando en la era de la investigación. Añadir más y más GPUs no será suficiente.
Sutskever y apoyadores apuntan cuestiones que todavía no serán resueltas con escalamiento en los modelos actuales y necesitan más investigación. Algunas de ellas son mencionadas a continuación:
- Los modelos de punta actuales sufren de “jaggedness” (irregularidad o fragmentación)[3], concepto que describe una contradicción: estos modelos pueden pasar en una compleja prueba de PhD, y fallar en ejecutar tareas muy sencillas, entrando en loops o teniendo alucinaciones. Esta desconexión sugiere que, si bien el pre-training (entrenamiento previo), característico de estos modelos, brinda un vasto conocimiento, no necesariamente les brinda la confiabilidad o la percepción de un experto humano.
- Otro reto está relacionado con el siguiente ejemplo: un adolescente aprende a manejar un auto en diez o veinte horas, mayormente sin supervisión y sin colidir millones de veces en una simulación. El desafío es descubrir el principio de aprendizaje de máquina que permita este tipo de generalización rápida y robusta, algo que el escalamiento falla en capturar.
- También un tema de interés es el rol de la emoción en la inteligencia. En el aprendizaje automático, una «función de valor» ayuda a un agente a decidir si una situación es buena o mala sin tener que esperar hasta el final. La IA actual está basada en recompensas externas (como un humano clicando “pulgares arriba”) o ambientes de aprendizaje por refuerzo[4]. Sutskever argumenta que las emociones humanas, nuestras «intuiciones», son esencialmente funciones de valor altamente eficientes y evolutivamente codificadas. La idea sería un sistema que, como humanos, aprenda haciendo.
Así, se sostiene que las mejoras exponenciales en las técnicas de IA no dependen del simple escalamiento de la capacidad computacional, sino principalmente de un retorno a los laboratorios y a proyectos de investigación profunda orientados al desarrollo de nuevos paradigmas de aprendizaje.
Impactos en las administraciones tributarias
La adopción de IA en administraciones tributarias es un tema complejo y no se atiene solamente a los riesgos en la evolución de los costos de infraestructura, tratado en este post, y la exposición a una “burbuja de IA”.
La toma de decisiones respecto a aspectos críticos para el éxito de la iniciativa abarca otros componentes, tales como arquitecturas y proveedores (evitar vendor lock-in y obsolescencia acelerada); modelos a ser utilizados y la estrategia para adoptarlos; cuestiones de privacidad y ética; establecimiento de ROI (KPIs) basados en el negocio (e.g., reducción de la brecha fiscal) y no en “modernidad”.
Por encima de todo esto se encuentran los datos, fundamentales para cualquier estrategia definida. Por lo tanto, establecer la gobernanza de datos debería ser una prioridad fundamental.
Asimismo, es importante seguir los avances del área para una toma de decisiones informada.
Bibliografía:
Véase https://bit.ly/3Lkunlr
Collosa, A. y Zambrano, R. (2025). La IA ya está aquí. Blog del CIAT. Disponible en: https://www.ciat.org/la-ia-ya-esta-aqui/
Nikhil. (2025). Ilya Sutskever : “Age of Scaling is Over. The Age of Research Has Begun”. Blog en Medium, noviembre 6, 2025. https://medium.com/modelmind/ilya-sutskever-age-of-scaling-is-over-the-age-of-research-has-begun-7506c4d0a89a
OECD. (2025). Tax Administration 2025: Comparative Information on OECD and other Advanced and Emerging Economies. OECD Publishing, Paris. https://doi.org/10.1787/cc015ce8-en
Wu, K., Jian, X., Du, R., Chen, J., & Zhou, X. (2023). Roughness Index for Loss Landscapes of Neural Network Models of Partial Differential Equations. https://arxiv.org/pdf/2103.11069
Referencias:
[1] Para más información, acceder (1) sobre destilación – IBM: https://bit.ly/49qQ2lc ; (2) sobre RAG – Google: https://cloud.google.com/use-cases/retrieval-augmented-generation?hl=es
[2] Véase https://www.ibm.com/think/insights/ai-economics-compute-cost
[3] Descripción académica del concepto puede encontrarse en Wu et al. (2023)
[4] El Aprendizaje por Refuerzo (Reinforcement Learning o RL) es un método de entrenamiento de IA basado en el principio de ensayo y error, muy similar a cómo se entrena a una mascota o cómo un humano aprende a jugar un videojuego. A diferencia del aprendizaje tradicional (donde le das a la IA ejemplos de «pregunta y respuesta»), en el RL la IA aprende interactuando con un entorno y recibiendo recompensas o castigos (fuente: keytrends.ai).
8,463 total views, 1 views today